I just want a ChatGPT to teach me something
OpenAI has a new model. But it's not GPT-5 (please, please, we just like how it feels increment a number!). It's called "o1-preview", and it's a GPT that's fine-tuned for chain-of-thought reasoning.
On one hand, chain-of-thought prompting has been possible all along with GPT-3+, and is widely used. Heck, you can find it on site called LearnPrompting.org.
But OpenAI has taken things a step further by (1) training this model to use chain-of-thought all the time and, (2) more importantly, hiding the chain-of-thought from users. We do get to see a kind of summary of the reasoning steps (at least in ChatGPT), but not the gory details of the LLM output. This might provide OpenAI some protection from other models training on o1 output, but it's a bummer.
I don't have access to op1 via API, but I do have it in ChatGPT. And it has no problem with the classic strawberry problem (LLMs struggle here because tokenization swallows letter-counts):
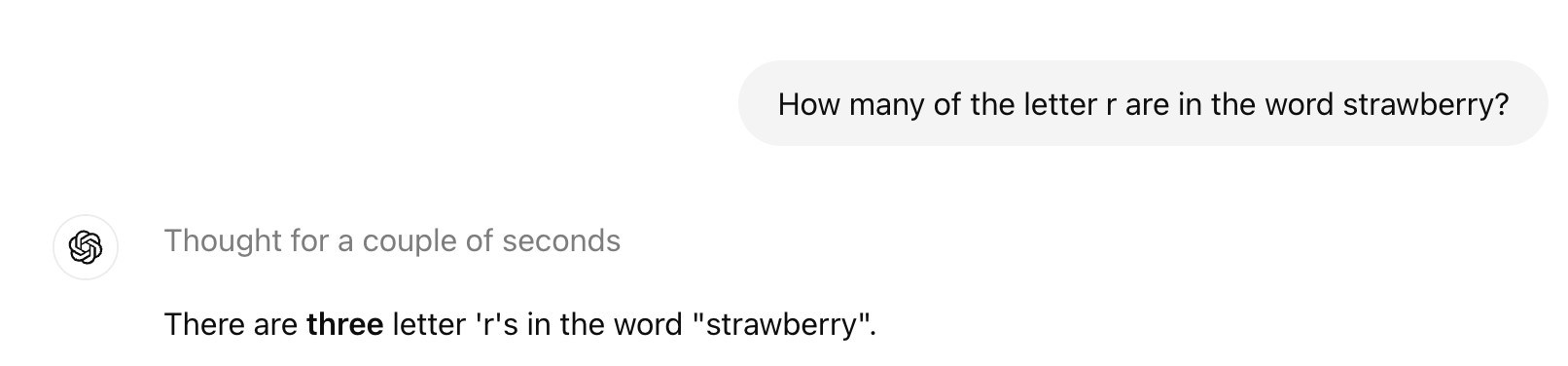
So, at least we have that. I like to challenge these models to teach me something; let's try that.
Let's make a syllabus
A fun and productive challenge that I like to give LLMs is to teach me a topic as though I'm in an advanced college course. Popular models ace the basics here: they can write out syllabi, they can give me a reading list, they can often find links to other courses, and they are an absolute fountain of knowledge on many topics.
But the way I like to learn (and I think many people are the same) is to receive some new information and then react: ask questions, try problem sets, do related research, and so on. LLMs are not nearly as good as I'd like when it comes to actual pedagogy.
For example, let's ask o1 to teach us about Blue Whales -- the Kings of the Sea.
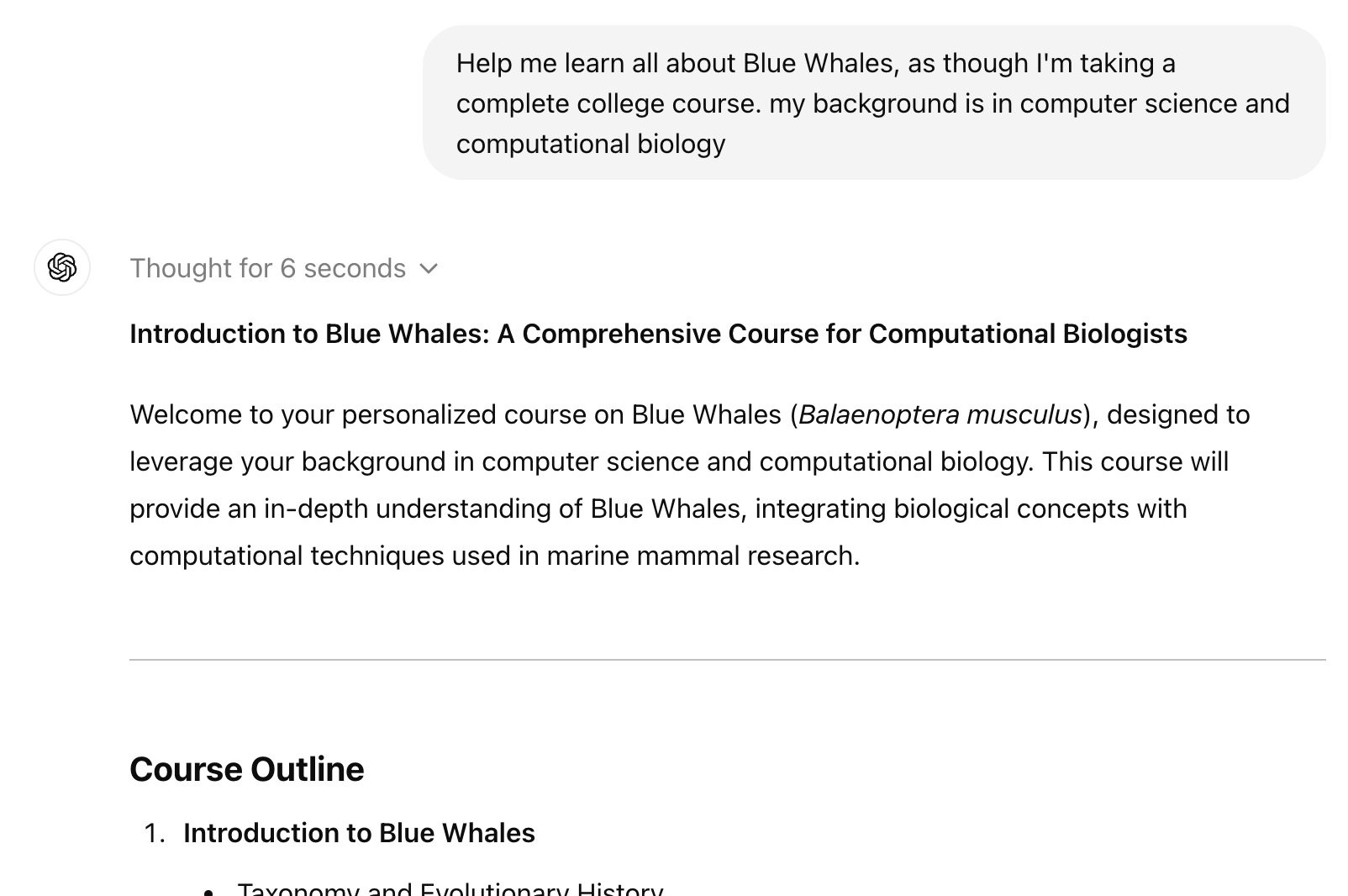
We start out OK, with some introduction, and a course outline. You can try this yourself to get a sense for the experience (works fine with GPT-4 as well -- I'll get to Claude in a second). I'm getting lots and lots and lots of details from the ChatGPT about Blue Whales. But it's not any fun: It's a million bullet points, and I'd rather read the Wikipedia page.
OK, let's tell o1 that we have a problem:

And ... we get another thousand bullet points. We're doing worse, not better.
Some clever prompting might get us in the ballpark of a good conversation, but I also find that I get lost navigating up and down the conversation history. It could be so much better.
What does Claude think?
So I figured I'd try Claude. And this was more exciting than o1, because I hadn't played with Claude much, and it has some clever tricks.
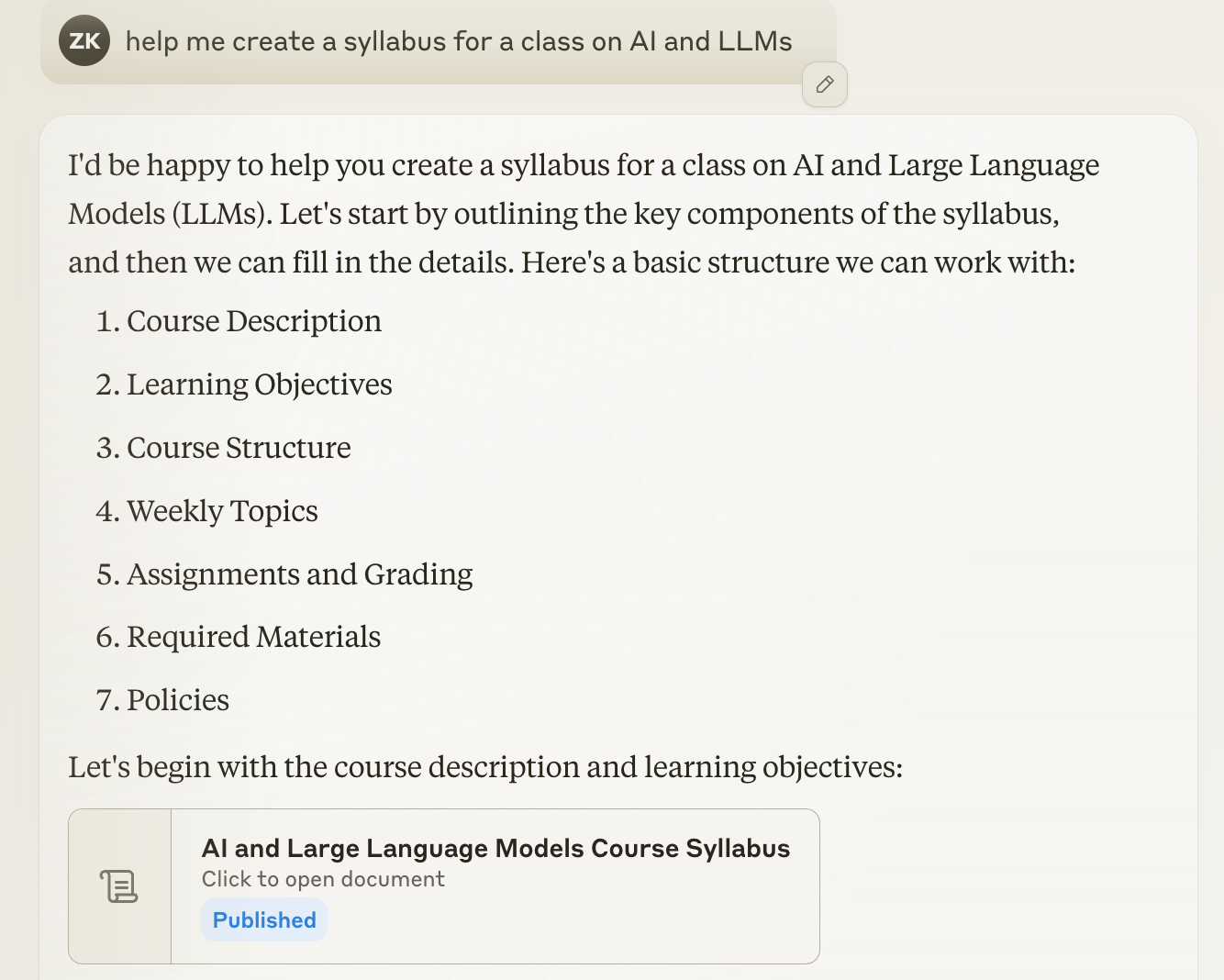
That's a document I can keep handy! It's actually called an artifact, and Claude can create and manage these for you. They feel so close to my instinct for what I want here: A conversation with a super smart friend on one side, and a bunch of content that I can browse through and organize on the other side. So far so good.
I asked Claude to edit that document, and instead it created a brand new one -- so there is some work to be done here.
It's not really about models at this point (though smarter models will certainly create better artifacts). It's about integrating models with a beautifully-designed interface that captures how we think and learn.
Last thing I tried before hanging up the keyboard: I asked Claud to create some lecture slides for me and even include images. It got clever -- TOO clever in my opinion, and built a React website for me. These slides are not remotely useful for learning:
https://claude.site/artifacts/a87ad762-94c0-4729-8b84-88b1c07faeb8
But they feel much closer to the end goal than the onslaught of bullet points that I survived in ChatGPT with o1.
Chain-of-thought another day?
I'm enormously bullish on chain-of-thought reasoning, because it feels to me like a perfect analogue of the way my brain seems to reason. I haven't found a killer application for the version in ChatGPT just yet -- the API will be extremely fun to play with when it's available. In the meantime, I hope every single offering in this space takes note of Anthropic's innovations on artifacts and brings these experiences to life.